Abstract
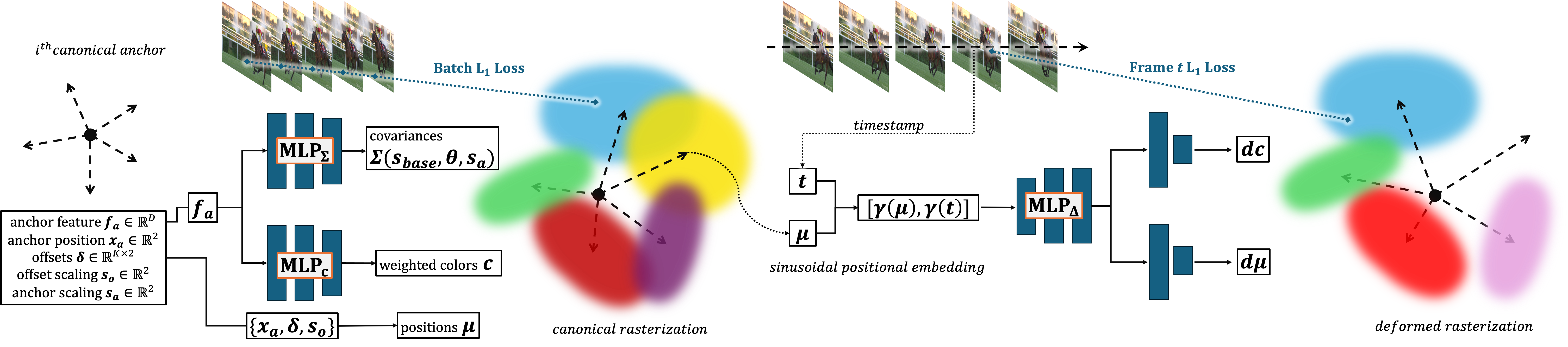
With the increasing use of video data across a wide range of domains including medical imaging, computer vision, and online streaming platforms, efficient and compact video representation is essential for cost-effective storage without sacrificing video fidelity. Recent methods in Deformable 2D Gaussian Splatting (D2GV) represent video using a canonical set of 2D Gaussians that are deformed over time to render individual frames. Compared to existing techniques in Implicit Neural Representations (INRs), D2GV achieves faster training and rendering times with strong video fidelity. However, storing and deforming Gaussian primitives independently ignores the spatial and temporal similarities among local Gaussians across frames. To exploit these similarities, we incorporate anchor-based neural Gaussians to utilize INR-based parameterization of Gaussian primitives for compact storage. We partition the video sequence into fixed-length subsequences to enable parallel training and linear scalability as the number of frames increases. For each subsequence, a canonical set of anchors is initialized across a structured grid, each governing a group of local Gaussian primitives. From stored anchor features, corresponding shape and color attributes of local Gaussians are predicted via two lightweight multi-layer perceptrons (MLPs). A third MLP is incorporated to predict deformations from anchored canonical frames to the individual frames across time. Our design improves compression ratios without significantly reducing fidelity while maintaining similar training and decoding times.